Data Quality#
This notebook shows some of the data quality functions associated with a Spectrum . The data used for this example is taken from position switched observations of NGC5291 at 21 cm (AGBT05B_047_01) that we discussed in previous notebooks.
Dysh commands#
The following Spectrum functions will be discussed:
stats : statistics of a spectrum
roll : subtract the data by its rolled version to discover channel correlations and/or ripples in the spectrum
radiometer : adherence of spectrum to the radiometer equation
normalness : p-value for null hypothesis that the data comes from a normal distribution
snr : signal-to-noise ratio, either channel or flux based
sratio : flux ratio, a number between -1 and 1, if there is signal, 0 if none
cog : curve of growth
Loading Modules#
We start by loading the modules we will use in this notebook.
# These modules are required for the data reduction.
import numpy as np
from astropy import units as u
from dysh.util.files import dysh_data
from dysh.spectra.spectrum import Spectrum
from dysh.fits.gbtfitsload import GBTFITSLoad
from dysh.log import init_logging
from pathlib import Path
Setup#
We start the dysh logging, so we get more information about what is happening.
This is only needed if working on a notebook.
If using the CLI through the dysh command, then logging is setup for you.
init_logging(2)
# also create a local "output" directory where temporary notebook files can be stored.
output_dir = Path.cwd() / "output"
output_dir.mkdir(exist_ok=True)
Data Loading#
We use the data from the tests for getps (AGBT05B_047_01). We load the data using GBTFITSLoad, and then its summary method to inspect its contents.
filename = dysh_data(test="getps") # AGBT05B_047_01/AGBT05B_047_01.raw.acs
sdfits = GBTFITSLoad(filename)
23:08:12.253 I Resolving test=getps -> AGBT05B_047_01/AGBT05B_047_01.raw.acs/
23:08:12.299 I Index loaded from .index file (44/93 columns). Missing columns (TCAL, WCS, calibration metadata, etc.) will be automatically loaded from FITS file when first accessed.
sdfits.summary()
| SCAN | OBJECT | VELOCITY | PROC | PROCSEQN | RESTFREQ | # IF | # POL | # INT | # FEED | AZIMUTH | ELEVATION |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 51 | NGC5291 | 4386.0 | OnOff | 1 | 1.420405 | 1 | 2 | 11 | 1 | 198.3431 | 18.6427 |
| 52 | NGC5291 | 4386.0 | OnOff | 2 | 1.420405 | 1 | 2 | 11 | 1 | 198.9306 | 18.7872 |
| 53 | NGC5291 | 4386.0 | OnOff | 1 | 1.420405 | 1 | 2 | 11 | 1 | 199.3305 | 18.3561 |
| 54 | NGC5291 | 4386.0 | OnOff | 2 | 1.420405 | 1 | 2 | 11 | 1 | 199.9157 | 18.4927 |
| 55 | NGC5291 | 4386.0 | OnOff | 1 | 1.420405 | 1 | 2 | 11 | 1 | 200.3042 | 18.0575 |
| 56 | NGC5291 | 4386.0 | OnOff | 2 | 1.420405 | 1 | 2 | 11 | 1 | 200.8906 | 18.1860 |
| 57 | NGC5291 | 4386.0 | OnOff | 1 | 1.420405 | 1 | 2 | 11 | 1 | 202.3275 | 17.3853 |
| 58 | NGC5291 | 4386.0 | OnOff | 2 | 1.420405 | 1 | 2 | 11 | 1 | 202.9192 | 17.4949 |
Data Reduction#
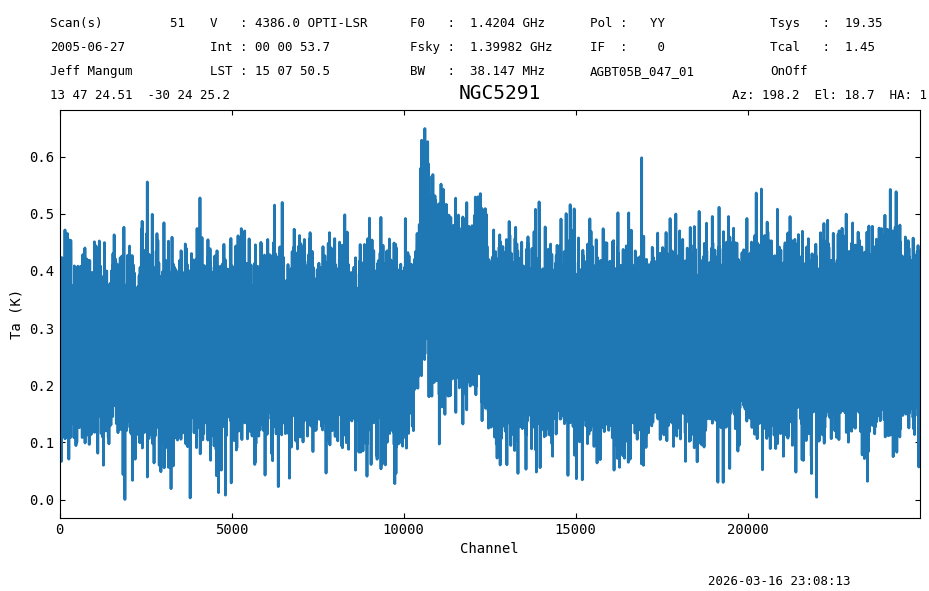
First we extract a (time-averaged) spectrum from the first scan. If you recall from the Position-Switched example, both edges have some problems, and for the purpose of this we remove some edge channels by slicing the Spectrum. We end by plotting the resulting Spectrum using channels for the x-axis.
sp1 = sdfits.getps(scan=51, ifnum=0, plnum=0, fdnum=0).timeaverage()[5000:30000]
plot1 = sp1.plot(xaxis_unit='chan');
# First 10,000 channels.
sp1[:10000].stats()
{'mean': <Quantity 0.26528673 K>,
'median': <Quantity 0.26475095 K>,
'rms': <Quantity 0.07121472 K>,
'min': <Quantity 0.00017927 K>,
'max': <Quantity 0.55562309 K>,
'npt': 10000,
'nan': np.int64(0)}
# Last 10,000 channels.
sp1[-10000:].stats()
{'mean': <Quantity 0.28550266 K>,
'median': <Quantity 0.28676712 K>,
'rms': <Quantity 0.07194848 K>,
'min': <Quantity 0.00420958 K>,
'max': <Quantity 0.59789101 K>,
'npt': 10000,
'nan': np.int64(0)}
There is a significant continuum visible in the spectrum, with a value of \({\approx}270\) mK, but the two sides differ a bit, in the sense there is slight increase towards higher channels. This is also visible in the previous plot.
The rms levels are very similar, at 0.0712 K and 0.0719 K respectively.
Roll#
The
roll
method compares the rms in the spectrum to the rms obtained after “rolling” the data by roll channels.
This method is useful for assessing if there are channel-to-channel correlations. In the abscence of correlations the result should be close to unity.
Correlations will drive the results away from unity.
However, the results from roll are also affected by slow variations in the data, as is the case with this spectrum.
We thus compare the first and second half.
It is possible to compute the statistics over a “rolled” version of the spectrum.
That is, before computing the statistics, the values from channel i+roll are subtracted from the values of channel i, to avoid
This accomplished using the roll argument in the call to stats.
When using roll!=0 the rms is divided by \(\sqrt{2}\) to account for the subtraction.
print(sp1[:10000].stats(roll=2)["rms"])
print(sp1[-10000:].stats(roll=2)["rms"])
0.07129852680478319 K
0.07117563979673236 K
Here we see the rolled RMS is very similar to the direct RMS, a sign that there is little or no correlation between channels, and that there are no large scale variations in the baseline.
sp1[:10000].roll(4)
[np.float64(1.0135264184344186),
np.float64(0.998824594091855),
np.float64(1.0009603155106295),
np.float64(1.0088321963615878)]
sp1[-10000:].roll(4)
[np.float64(0.9999156099029664),
np.float64(1.0108582257308132),
np.float64(1.0084001989693765),
np.float64(0.9975490048638298)]
Here one can argue there is no correlation between channels, and there is little large scale variation in the baseline. Note we have not subtracted a baseline, so we will need to do this again later in the notebook.
Radiometer Equation#
For a given \(T_{sys}\), channel width \(\Delta f\) and observing time \(\Delta t\) the radiometer equation predicts the expected noise as:
For example, if we blindly compute this test we will get a value larger than one, because of line emission between channels 10000 and 13000.
sp1.radiometer()
np.float64(1.1252550964360961)
When we compute it on line-free channels the results are closer to unity.
print(sp1[:10000].radiometer(), sp1[-10000:].radiometer())
1.0534482574016264 1.064302431580704
However, the measured noise (rms) is still \({\approx}6\%\) larger than expected.
For comparison, we compute this statistic in the case of a purely Gaussian signal. We do this using the fake_spectrum method, which returns a spectrum filled with Gaussian noise.
Spectrum.fake_spectrum(nchan=32768, seed=123).radiometer()
np.float64(1.000493959432403)
The exact value is a function of the number of channels in the spectrum, and it goes as \(1/\sqrt{N}\). Experiments showed that for nchan=32768 the rms in this ratio is about 0.004.
Normalness#
The normalness method gives the likelihood that the spectrum data is drawn from a normal distribution. Under the hood this method computes the Anderson-Darling statistic and returns the p-value of the likelihood that the data is normally distributed. A p-value larger than 0.05 indicates that the data is consistent with being drawn from a normal distribution.
We start by computing the normalness test for the line-free regions, and then we compute it for the whole spectrum.
print(sp1[:10000].normalness())
print(sp1[-10000:].normalness())
0.5988494829518621
0.3155802929161549
These values are larger than 0.05, so the line-free regions are consistent with Gaussian noise. For amusement, the whole spectrum:
print(sp1.normalness())
2.5779119487111985e-09
In this case the p-value is lower than 0.05, indicating that the null-hyphotesis can be rejected, that is, the data is not drawn from a normal distribution. That is the case because of the line between channels 10000 and 13000.
Baseline Subtraction#
The remaining data quality tests, the signal-to-noise ratio and signal ratio, only make sense if the data has no continuum. In this case that requires subtracting a baseline from the data.
We know that there is a line between channels 10000 and 13000, so we exclude these channels from the baseline fit using the exclude argument of
baseline .
We saw earlier that there’s a slope to the data, so we use a degree 2 polynomial for the baseline model, to to ensure any curvature is removed as well. Again, these things can later be tested.
We remove the best fit polynomial model from the data (remove=True).
sp1.baseline(degree=2, model="poly", exclude=[10000,13000], remove=True)
23:08:15.952 I EXCLUDING [Spectral Region, 1 sub-regions:
(1397351017.8086 Hz, 1401928654.52735 Hz)
]
Plot the baseline subtracted spectrum and print its statistics.
sp1.plot(xaxis_unit='chan');
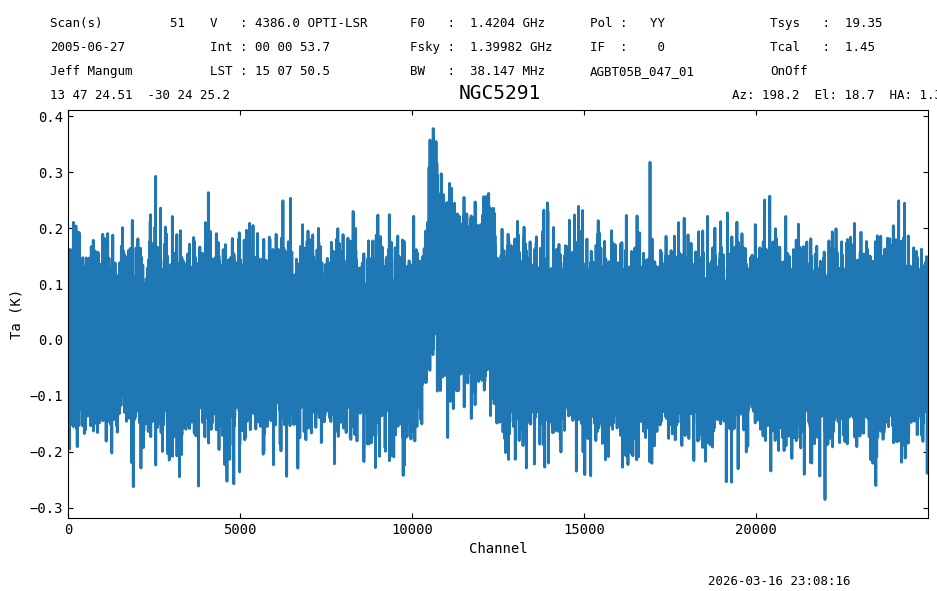
sp1[:10000].stats()
{'mean': <Quantity -2.26296993e-05 K>,
'median': <Quantity -0.00075626 K>,
'rms': <Quantity 0.07116939 K>,
'min': <Quantity -0.26237536 K>,
'max': <Quantity 0.29259242 K>,
'npt': 10000,
'nan': np.int64(0)}
sp1[-10000:].stats()
{'mean': <Quantity -0.00022584 K>,
'median': <Quantity 0.00077847 K>,
'rms': <Quantity 0.071728 K>,
'min': <Quantity -0.28504302 K>,
'max': <Quantity 0.31773396 K>,
'npt': 10000,
'nan': np.int64(0)}
snr: Signal-to-Noise Ratio#
The
snr
method computes the signal-to-noise ratio of the spectrum.
This can be done in two ways: channel based and flux based.
For the latter a section of the spectrum where the signal is expected has to be selected.
For the channel based analysis, it will compute the ratio between the maximum value (peak=True, default) and the noise.
For an absorption signal one can use peak=False where the minimum is used instead.
For pure noise in a channel based comparision (the default) we would expect the signal-to-noise to be around 4, higher for higher number of channels, as can be computed via the error function.
print(sp1[:10000].snr(), sp1[-10000:].snr())
4.164491209380744 4.418897606868031
Now we repeat the snr call, but using the flux instead.
We show the results for the line-free regions of the spectrum and for the section with the line.
print(sp1[:10000].snr(flux=True))
print(sp1[-10000:].snr(flux=True))
print(sp1[10000:13000].snr(flux=True))
-0.032206540254367526
-0.31387167706372504
47.65735422463844
The line-free regions have a signal-to-noise of \(<0.5\), so no signal in them. Channels 10000 to 13000 have a signal-to-noise ratio of \(47\). Really it should be called flux-to-error ratio.
Applying this to the whole spectrum, we still get a respectable ratio of over 5:
sp1.snr()
np.float64(5.202717707400019)
sratio: Signal Ratio#
The sratio (signal ratio) is defined as the sum between the positive and negative sum of the signals, normalized by the difference of both. This results in a dimensionless number between -1 and 1, where -1 means a pure absorption signal, 0 pure noise, and 1 pure emission line:
We compute this for the line-free channels, where we expect values close to zero (no signal).
print(sp1[:10000].sratio())
-0.0003992688164057342
print(sp1[-10000:].sratio())
-0.003947589621888944
And now the channels with the line.
print(sp1[10000:13000].sratio())
0.7404518589686879
In this case we have a value of \(0.74\), close to unity, indicating an emission line.
Repeat statistics, roll and radiometer#
Now that the spectrum has been baseline subtracted we can repeat the analysis carried out above.
# redo the tests
print(sp1[:10000].stats())
print(sp1[:10000].stats(roll=1))
print("ROLL",sp1[:10000].roll(4))
print(sp1[-10000:].stats())
print(sp1[-10000:].stats(roll=1))
print("ROLL",sp1[-10000:].roll(4))
{'mean': <Quantity -2.26296993e-05 K>, 'median': <Quantity -0.00075626 K>, 'rms': <Quantity 0.07116939 K>, 'min': <Quantity -0.26237536 K>, 'max': <Quantity 0.29259242 K>, 'npt': 10000, 'nan': np.int64(0)}
{'mean': <Quantity -1.91970331e-06 K>, 'median': <Quantity -0.00102835 K>, 'rms': <Quantity 0.0702643 K>, 'min': <Quantity -0.37160137 K>, 'max': <Quantity 0.35925086 K>, 'npt': 9998, 'nan': np.int64(0)}
ROLL [np.float64(1.0128811836035871), np.float64(0.9981887196390057), np.float64(1.0003230829955267), np.float64(1.0081899539027515)]
{'mean': <Quantity -0.00022584 K>, 'median': <Quantity 0.00077847 K>, 'rms': <Quantity 0.071728 K>, 'min': <Quantity -0.28504302 K>, 'max': <Quantity 0.31773396 K>, 'npt': 10000, 'nan': np.int64(0)}
{'mean': <Quantity 1.49875702e-05 K>, 'median': <Quantity 7.21955806e-06 K>, 'rms': <Quantity 0.07195455 K>, 'min': <Quantity -0.36167572 K>, 'max': <Quantity 0.36903475 K>, 'npt': 9998, 'nan': np.int64(0)}
ROLL [np.float64(0.9968514885721491), np.float64(1.0077605735034652), np.float64(1.0053100804345212), np.float64(0.9944921404674939)]
print(sp1[:10000].radiometer(), sp1[-10000:].radiometer())
1.052777606911913 1.0610410041607696
Curious how the radiometer equation holds as function of time?
for scan in [51,53,55,57]:
sp2 = sdfits.getps(scan=scan, ifnum=0, plnum=0, fdnum=0).timeaverage()[5000:30000]
print(scan, sp2[:10000].radiometer(), sp2[-10000:].radiometer())
51 1.0534482574016264 1.064302431580704
53 1.040350406935904 1.0625100007245583
55 1.0583714842277552 1.0546632159969935
57 1.0434732937008273 1.0579653655733117
So we can conclude it did not change behavior during this observation, but there is a clear 5-6% deviation from an ideal telescope.
Smoothing#
Smoothing should give us a much clearer detection. We smooth the data using a Hanning kernel with a width of 50 channels. Lets see how the previous measures live of to this task.
n = 50
method = 'hanning'
sp1s = sp1.smooth(method, n)
sp1s.plot(xaxis_unit='chan')
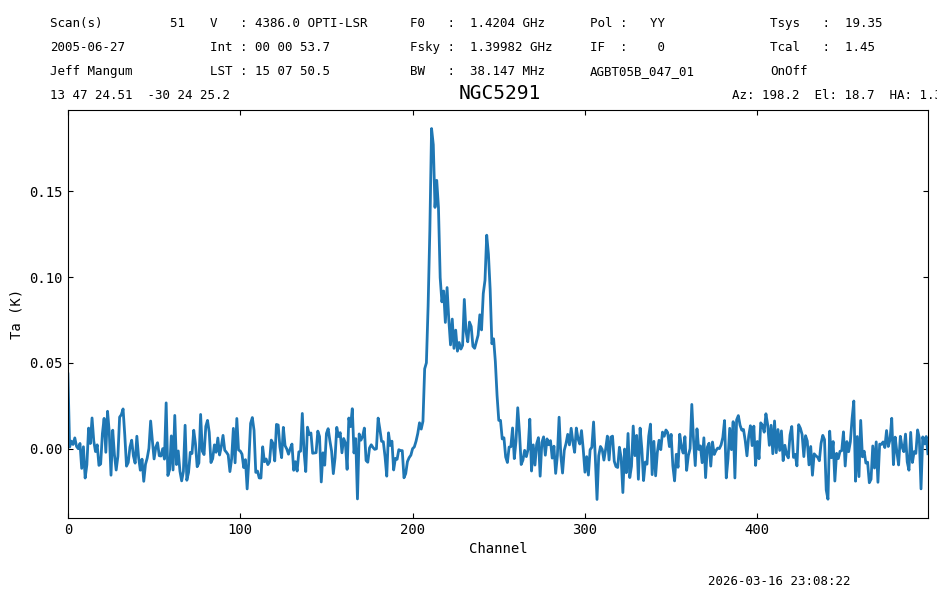
<dysh.plot.specplot.SpectrumPlot at 0x7c7bd5314910>
The line is now between channels 200 and 260.
Lets print the rms for this smoothed signal. Unsmoothed we found 0.07 K so we should expect \(\sqrt{50}\) better, or about 0.01 K.
print(sp1s[:200].stats()["rms"], sp1s[-200:].stats()["rms"])
0.010752784984015665 K 0.01054986378504788 K
Smoothing reduced the noise as expected.
Now the radiometer equation test.
print(sp1s[:200].radiometer())
print(sp1s[-200:].radiometer())
1.1247328739459046
1.1035074757222016
In this case the test suggests that the data is worse than before (it was \(5\%\) higher, now it is \(11\%\)). This could be an artifact of dysh, and is being investigated in issue 917
Now the signal-to-noise ratio.
print("Signal-to-Noise by channel")
print(sp1s[:200].snr(peak=True), sp1s[:200].snr(peak=False), 'left side')
print(sp1s[-200:].snr(peak=True), sp1s[-200:].snr(peak=False), 'right side')
print(sp1s[200:260].snr(peak=True), sp1s[200:260].snr(peak=False), 'central signal portion')
Signal-to-Noise by channel
4.484230565824752 3.0157797607093078 left side
2.6415172968433853 2.7987663047629003 right side
9.702435844984779 5.432313027221527 central signal portion
print("Signal-to-Noise by flux")
print(sp1s[:200].snr(flux=True), 'left side')
print(sp1s[-200:].snr(flux=True), 'right side')
print(sp1s[200:260].snr(flux=True), 'central signal portion')
Signal-to-Noise by flux
-0.15450022584030138 left side
-0.24202494585764245 right side
37.169404072966664 central signal portion
Notice that the signal-to-noise in the line intensity is now lower than before (it was \({\approx}47\)).
That is because the snr method uses the data itself to determine the noise.
Since we are using a channel range that mostly contains signal, the noise estimate is higher, thus reducing the signal-to-noise ratio.
We can give our own estimate of the noise using the rms parameter when calling snr.
Like
print(sp1s[200:260].snr(flux=True, rms=sp1s[-200:].stats()["rms"]), 'center signal portion with given rms')
45.34448732737641 center signal portion with given rms
This is closer to the previous estimate. It also shows that smoothing the data does not improve the signal-to-noise ratio on the line intensity for this velocity resolved line.
And the signal ratio.
sp1s[200:260].sratio()
np.float64(0.9898058259803745)
a value very close to 1, so a clear signal.
This brings up the question of statistical significance. Unlike the normalness() function, we don’t get a p-value out of this sratio. We would have to compute this ourselves,
by doing a monte-carlo type experimen.
The somewhat compute intensive cell below does exactly that.
%%time
m=100 # number of experiments
d=np.zeros(m) # array containing the sratio values
n=32768 # largest size of spectrum
for nchan in [n, n//4, n//4//4, n//4//4//4]:
for i in range(m):
sp = Spectrum.fake_spectrum(nchan=nchan, seed=i, use_wcs=False) # no WCS to save time
sp._data = sp._data - 0.1 # current fake_spectrum has hardcoded mean 0.1 - sp.data has no setter
d[i] = sp.sratio()
print(d.mean(),d.std(),nchan,m)
2.5915644138152958e-05 0.0072313682098405704 32768 100
0.0012918880805727934 0.014393322246256487 8192 100
0.0004981238315851011 0.029646394585039575 2048 100
0.008433098305909085 0.05710832059113764 512 100
CPU times: user 4.09 s, sys: 15 ms, total: 4.11 s
Wall time: 4.11 s
# plot histogram of last nchan loop with 512 channels
import matplotlib.pyplot as plt
plt.hist(d, bins="auto");
plt.xlabel("sratio value");
plt.ylabel("Counts")
plt.show()
/home/docs/checkouts/readthedocs.org/user_builds/dysh/envs/release-1.0.0/lib/python3.10/site-packages/traitlets/traitlets.py:1385: DeprecationWarning: Passing unrecognized arguments to super(Toolbar).__init__().
NavigationToolbar2WebAgg.__init__() missing 1 required positional argument: 'canvas'
This is deprecated in traitlets 4.2.This error will be raised in a future release of traitlets.
warn(
The RMS follows the expected \(1/\sqrt{N}\) behavior, and for given \(N\) one can assign a p-value based on the error function if this distribution is normal. We leave this as an exercise for the reader.
Curve of Growth#
The Curve of Growth method (Yu et al. 2020) also lists lots of interesting properties that can be used in some of the quality assessment functions we have discussed above.
We merely show the result of the cog function here, and plot the spectrum now in units of km/s:
sp1s.cog()
23:08:29.318 I Velocity frame: Topocentric
23:08:29.318 I Doppler convention: optical
{'flux': <Quantity 60.7548381 K km / s>,
'flux_std': <Quantity 1.67196758 K km / s>,
'flux_r': <Quantity 29.4009652 K km / s>,
'flux_r_std': <Quantity 1.94644775 K km / s>,
'flux_b': <Quantity 31.41728474 K km / s>,
'flux_b_std': <Quantity 1.46281975 K km / s>,
'width': {0.25: <Quantity 215.4868403 km / s>,
0.65: <Quantity 447.54977747 km / s>,
0.75: <Quantity 513.85353672 km / s>,
0.85: <Quantity 580.15733259 km / s>,
0.95: <Quantity 679.61310541 km / s>},
'width_std': {0.25: <Quantity 33.22178748 km / s>,
0.65: <Quantity 16.80630176 km / s>,
0.75: <Quantity 33.54775629 km / s>,
0.85: <Quantity 33.65571145 km / s>,
0.95: <Quantity 33.8413805 km / s>},
'A_F': np.float64(1.068580045741405),
'A_C': np.float64(1.211663903123233),
'C_V': np.float64(2.6923098031876593),
'rms': <Quantity 0.01055038 K>,
'bchan': np.int64(185),
'echan': np.int64(267),
'vel': <Quantity 4382.45068039 km / s>,
'vel_std': <Quantity 440.84330695 km / s>,
'vframe': 'itrs',
'doppler_convention': 'optical'}
sp1s.plot(xaxis_unit='km/s')
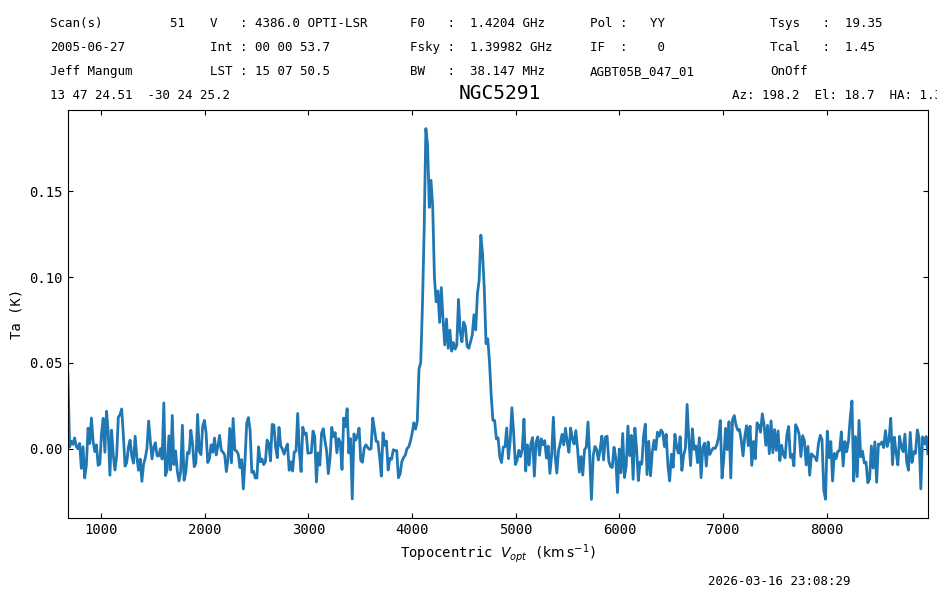
<dysh.plot.specplot.SpectrumPlot at 0x7c7bd52948e0>
Final Stats#
Finally, at the end we compute some statistics over a spectrum, merely as a checksum if the notebook is reproducible.
sp1s.check_stats(0.02744442 * u.K)
23:08:29.658 I rms is OK